
Una publicación del blog de Gartner cuyo título es «El futuro de los sistemas de gestión de bases de datos es la nube» hace la afirmación de que la nube pública es ahora la plataforma predeterminada para administrar datos. El artículo se basa en una investigación realizada por Donald Feinberg, Merv Adrian y Adam Ronthal, que son veteranos de la industria con una larga experiencia en el mercado de DBMS.
El artículo hace las siguientes afirmaciones:
- La nueva innovación DBMS ahora solo está en la nube o al menos en la nube primero. Si no estás en la nube te lo perderás.
- Los modelos de precios que evitan los gastos de capital a favor de los gastos operativos están impulsando el movimiento. En otras palabras, esta es una tendencia a largo plazo impulsada por la economía básica, por lo que podemos esperar que continúe y tal vez incluso se intensifique con el tiempo.
Estas afirmaciones son potencialmente engañosas. Si está diseñando sistemas para administrar datos, tomarlos al pie de la letra podría generar serios errores estratégicos. Puede perderse tecnología competitiva y también limitar la rentabilidad de su negocio.
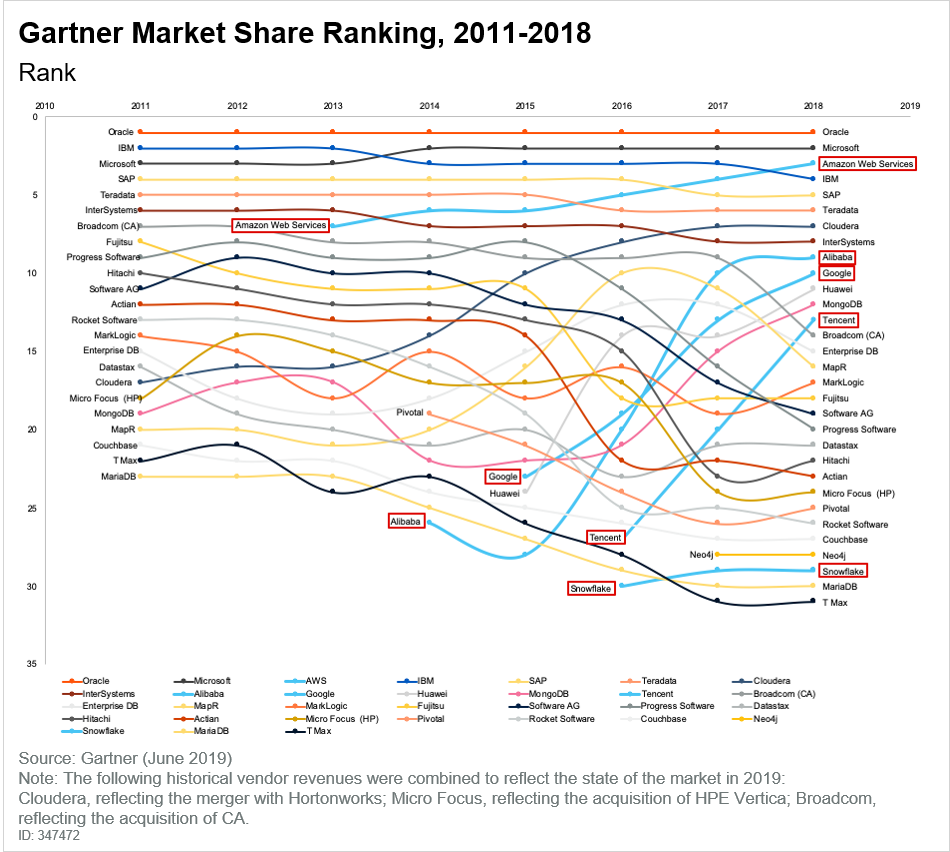
Pueda leer usted mismo investigación de Gartner.
El software de código abierto es fundamental para la innovación en la gestión de datos.
El ranking de participación de mercado de Gartner no menciona ClickHouse , que es un gran almacén de datos y muchas otras excelentes tecnologías de código abierto también se quedaron fuera. Faltan bases de datos de series temporales como InfluxDB y TimescaleDB. Faltan MySQL y PostgreSQL. Esta última omisión es notable ya que ambas bases de datos son ejes de Amazon RDS, uno de los servicios de datos en la nube pública más exitosos.
Más sorprendentemente, las tecnologías de IA no se mencionan. El aprendizaje automático y el aprendizaje profundo representan el mayor avance en el análisis de datos de la última década. Además del acoplamiento cercano de las tuberías de AI con las bases de datos, la capacitación y ejecución de modelos está comenzando a integrarse directamente en el DBMS. Cualquier enumeración actual de kits de herramientas de IA necesitaría incluir Scikit-Learn, Tensorflow, Torch, Keras y muchos otros marcos de código abierto. Proyectos como Apache Arrow prometen nuevas formas de integrarlos con DBMS sin copiar de manera ineficiente del almacenamiento a la ejecución de fuentes de información. Este es un espacio para observar con mucho cuidado, especialmente porque gran parte de la innovación se está produciendo en código abierto.
Finalmente, no podemos pasar por alto el papel emergente de Kubernetes en la gestión de datos. Confiere gran parte de la alta utilización y facilidad de administración que las nubes públicas ofrecen hoy en día. Nuestra propia experiencia en la construcción de ClickHouse Kubernetes Operator, así como la experiencia de los clientes, muestra que Kubernetes es un entorno viable para aplicaciones analíticas a gran escala. Kubernetes funciona igual de bien en entornos de nube y de metal desnudo, lo que permite a los usuarios ejecutar fácilmente proyectos portátiles de código abierto como ClickHouse en ambos. Kubernetes también es de código abierto.
No descartamos las innovaciones sobresalientes de los servicios de nube pública como Amazon RDS y Amazon Redshift. Ambos han sido cambiadores de juego al reducir el costo de entrada y facilitar la sobrecarga administrativa. Del mismo modo, servicios como Google BigQuery pueden operar en una escala enorme al ordenar eficientemente los recursos de la nube. Todas estas innovaciones son dignas de emulación. También hacen que los servicios de datos en la nube sean excelentes opciones para muchos problemas empresariales.
Dicho esto, si está tomando decisiones sobre sistemas futuros, debe mirar cuidadosamente el código abierto. En las últimas dos décadas, muchas de las tecnologías de gestión de datos más disruptivas han surgido de proyectos de código abierto. Una industria activa de capital de riesgo asegura que los mejores proyectos se conviertan rápidamente en productos empresariales. La rápida evolución de la analítica, la IA y Kubernetes a través de proyectos colaborativos de código abierto demuestra que esta tendencia continuará.
En resumen, los profesionales de gestión de datos que apartan la vista de la tecnología de código abierto corren el riesgo de verse muy sorprendidos. Es clave para gran parte de la innovación en el campo.
La economía de la nube pública no es adecuada para muchos casos de uso de gestión de datos
Es indiscutible que los servicios de nube pública funcionan de manera brillante para muchas empresas. Bajos costos iniciales, el hecho de que los proveedores manejan la administración de sistemas complejos y las economías de escala hacen que el uso de las nubes públicas sea obvio para muchos propósitos, no solo para la administración de datos. Las cifras de crecimiento de los ingresos en la nube demuestran ampliamente el atractivo.
¿Pero se deduce que la nube pública es adecuada para cada caso de uso? La respuesta es enfáticamente no. ¿Qué pasa si tiene un negocio con las siguientes características?
- Grandes cantidades de datos.
- Alta y constante utilización de recursos
- Sensibilidad de alto costo
Este perfil describe a los proveedores de SaaS más grandes, así como a las empresas de redes sociales como Facebook. Si la nube es universalmente buena para estas empresas, deberíamos esperar ver la mayoría de ellas funcionando allí. Sin embargo, el registro real es muy variado. Empresas como Lyft y Pinterest son los principales usuarios de los servicios de nube pública. Pero otros proveedores no se alejan o se han alejado de la nube pública a medida que crecieron.
SalesForce tiene un pequeño porcentaje de operaciones en AWS, pero utiliza en gran medida centros de datos que administra directamente . Facebook tiene una larga historia de construcción y operación de sus propios centros de datos desde cero. Dropbox originalmente alojado en AWS, pero en gran parte movió el almacenamiento de archivos fuera de Amazon a sus propios centros de datos. En el camino se afirmaron ahorro de $ 74,6 millones.
Esta última cifra llega al punto. Los servicios en la nube son caros. ¿Por qué el mercado de valores ama las nubes de Amazon y Azure? Simple: tienen excelentes márgenes brutos, que es el dinero que queda después de entregar el servicio a los clientes. Los informes recientes de ganancias de Microsoft indican que los márgenes brutos de MS Azure son al menos del 50%. Amazon no desglosa los márgenes brutos de AWS, pero muestra márgenes operativos consistentes (es decir, con otros gastos como las ventas) del 25% o más. Por lo tanto, supongamos que los márgenes brutos de AWS también son al menos del 50%.
Lo que ese 50% significa es simple para los usuarios. En promedio, si gasta $ 100 millones al año en la nube pública como lo hace Lyft , $ 50 millones van al balance del proveedor de la nube. Si ejecuta los servicios en sus propios centros de datos, $ 50 millones se destinan a su propio balance. Podemos verificar esta matemática mirando los números de Dropbox cuidadosamente, muestran ahorros en 2016 de alrededor del 43%. Para las empresas que son grandes, utilizan plenamente los recursos y son sensibles a los costos, los incentivos económicos son obvios y crecen con el tiempo.
Los incentivos también se desarrollan de una manera más sutil. En lugar de alejarse de Amazon o Azure, solo evite los servicios más caros. Eso incluye servicios de gestión de datos como Amazon RDS. Ejecutar una instancia db.m5.12xlarge en RDS MySQL puede ser un 80% más costoso que una instancia simple m5.12xlarge en la misma región. (Estimación basada en el término estándar de 3 años, región us-west-2). En su lugar, puede ejecutar MySQL de código abierto en cómputo y almacenamiento básicos. Eso reduce los costos y preserva la libertad de mudarse a otro lugar en el futuro. Curiosamente, eso es exactamente lo que empresas como Slack parecen estar haciendo.
En resumen, los incentivos para operar en la nube se desvanecen o incluso se invierten a medida que aumentan los ingresos comerciales. Independientemente del modelo de negocio, el costo operativo de los recursos de TI tiende a revertirse a la media a escala, lo que se correlaciona con los márgenes brutos del proveedor de la nube. Incluso si permanece en la nube, hay incentivos decrecientes para usar los servicios de datos en la nube. Estos son aspectos económicos básicos que afectan a cualquier negocio basado en datos.
Edge computing está creando nuevos casos de uso fuera de la nube
A largo plazo, el crecimiento explosivo de datos de dispositivos IoT promoverá la gestión fuera de las nubes públicas. Según una estimación, un solo auto de prueba autónomo genera datos a 3.000 veces la tasa de Twitter . Por razones que incluyen restricciones de ancho de banda de red, seguridad, límites de almacenamiento y la necesidad de responder en tiempo real, gran parte de estos datos se limpiarán, analizarán y usarán localmente. Solo una pequeña fracción llegará a la nube.
Es común en la gestión de datos en la nube hablar de la gravedad de los datos como una razón para que las aplicaciones se trasladen a la nube . Edge computing e IoT crean un nuevo tipo de gravedad de datos fuera de las nubes públicas. En muchos casos, dichos datos locales alcanzarán volúmenes que antes solo se veían en centros de datos centralizados.
Por lo tanto, esperamos que capacidades como mensajes de alta velocidad, consultas de transmisión y almacenes de datos con compresión eficiente aparezcan en entornos marginales. Algunos de estos serán los mismos productos y plataformas utilizados en las nubes públicas. Es una de las razones por las que creemos que la portabilidad sigue siendo una consideración importante para la tecnología de gestión de datos. Pero también esperamos una nueva innovación centrada en procesar datos rápidamente en entornos remotos. Parte de esa innovación ya es visible desde iniciativas como el Laboratorio UC Berkeley RISE, que incluye IA segura y en tiempo real. Muchos otros están trabajando en este problema.
Conclusión: piensa más allá de la nube
De acuerdo a Gartner en la nube es importante para la gestión de datos. Debe tenerse en cuenta en cada nueva decisión de implementación, especialmente en los casos en que la velocidad y la flexibilidad superan el costo.
Al mismo tiempo, los diseñadores de sistemas deben buscar nuevos proyectos de gestión de datos de código abierto como ClickHouse, que pueden conferir ventajas disruptivas a los primeros usuarios. Los diseñadores y los líderes empresariales también deben comprender que los incentivos económicos en la nube cambian significativamente a medida que crece el negocio. Finalmente, la informática de punta y el IoT impulsarán una nueva ola de tecnología para la gestión de datos. Muchas innovaciones serán aplicables no solo en el límite sino en todas las empresas basadas en datos.
Como ingenieros, a menudo hablamos sobre el diseño de sistemas para la escala. La gestión de datos escalable permite negocios escalables. Para alcanzar la meta debes pensar más allá de la nube.
Esta es una traducción no oficial del artículo «Far More than Cloud: Thoughts on the Future of Database Management Systems» que lo puedes encontrar en: